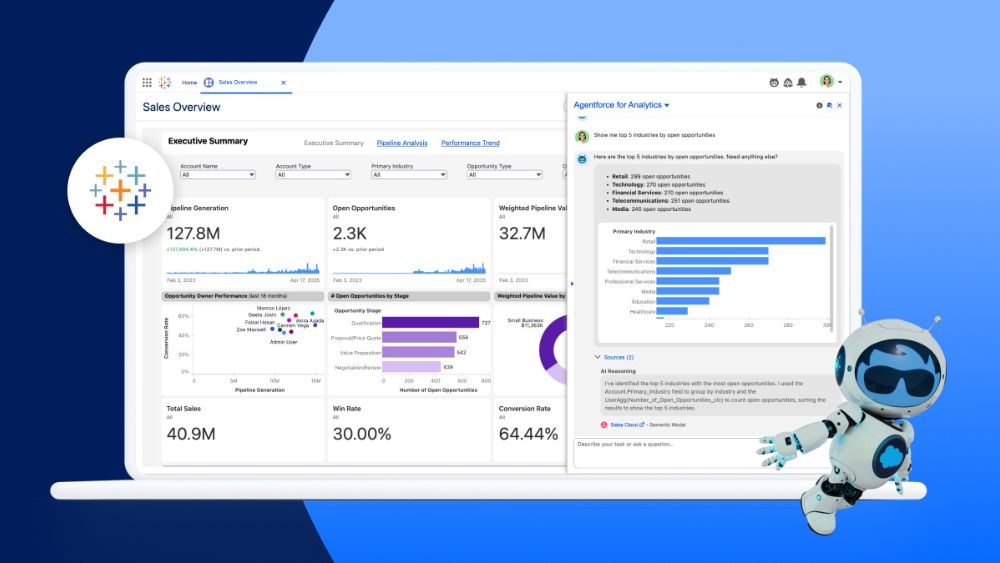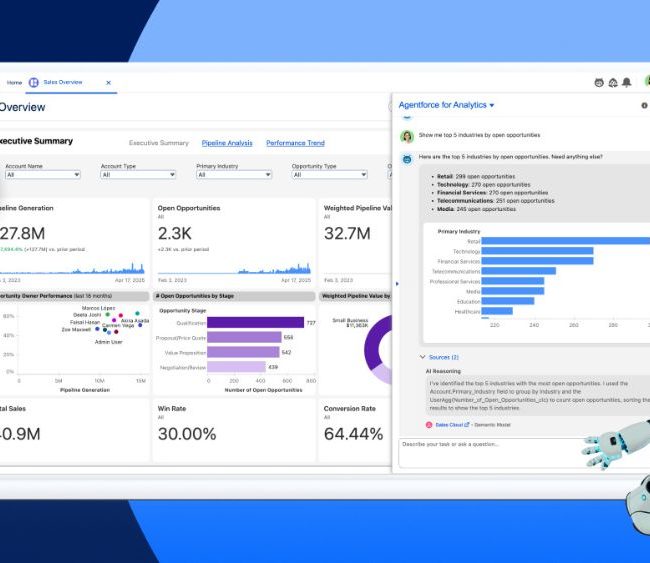


El databricks ingest representa uno de los pilares fundamentales para implementar una estrategia de datos exitosa en la era del análisis moderno. En un mundo donde las organizaciones generan volúmenes masivos de información desde múltiples fuentes, la capacidad de ingerir datos de forma eficiente y confiable se ha convertido en el diferenciador clave entre empresas que toman decisiones basadas en datos y aquellas que siguen operando con información fragmentada. La plataforma Databricks ofrece capacidades avanzadas de ingesta que permiten consolidar, transformar y analizar datos desde cualquier origen hacia un entorno unificado, estableciendo las bases para convertirse en una organización verdaderamente data-driven.

¿Por qué «databricks ingest» es clave en tu estrategia de datos?
La ingesta de datos en Databricks se ha posicionado como elemento central en las arquitecturas de datos modernas debido a su capacidad para manejar la complejidad inherente de los ecosistemas de información actuales. Las organizaciones enfrentan el desafío de integrar datos estructurados y no estructurados provenientes de sistemas transaccionales, aplicaciones SaaS, dispositivos IoT, redes sociales y múltiples fuentes en tiempo real.
El databricks ingest resuelve estos desafíos mediante una plataforma unificada que elimina los silos de datos tradicionales. Su arquitectura nativa en la nube permite escalar automáticamente según las necesidades de procesamiento, mientras que sus capacidades de procesamiento distribuido garantizan rendimiento óptimo incluso con volúmenes masivos de información.
La importancia estratégica radica en que una ingesta mal implementada puede convertirse en el cuello de botella que limite toda la cadena de valor analítico. Por el contrario, una estrategia de ingesta bien diseñada acelera el time-to-insight y permite que los equipos de análisis se concentren en generar valor empresarial en lugar de resolver problemas técnicos de integración.
¿Qué significa «databricks ingest»?
Databricks ingest se refiere al conjunto de procesos, herramientas y metodologías que permiten la captura, transformación y carga de datos desde múltiples fuentes hacia el entorno de análisis unificado de Databricks. Este concepto va más allá de la simple extracción de datos; implica la implementación de pipelines robustos que garanticen la calidad, integridad y disponibilidad de la información.
Desde una perspectiva técnica, el databricks ingest opera sobre la arquitectura Lakehouse, que combina las ventajas de los data lakes tradicionales con las capacidades transaccionales de los data warehouses. Esta arquitectura permite almacenar datos en su formato nativo mientras se mantienen las garantías ACID necesarias para análisis críticos.
El proceso de ingesta en Databricks se fundamenta en Apache Spark como motor de procesamiento distribuido, lo que permite manejar cargas de trabajo tanto batch como streaming con el mismo framework subyacente. Esta unificación tecnológica simplifica la gestión operativa y reduce la complejidad arquitectónica que tradicionalmente requería múltiples herramientas especializadas.
La plataforma implementa un enfoque declarativo para la definición de pipelines de ingesta, donde los desarrolladores especifican qué transformaciones aplicar sin preocuparse por los detalles de implementación distribuida. Esta abstracción acelera significativamente el desarrollo y mantenimiento de los procesos de ingesta.
Tipos de ingestión en Databricks: batch, streaming y CDC
Ingestión por lotes (Batch)
La ingestión batch en Databricks está diseñada para procesar grandes volúmenes de datos de forma programada o bajo demanda. Este enfoque resulta ideal para cargas de trabajo periódicas donde la latencia no es crítica, como reportes diarios, procesos de consolidación mensual o migraciones históricas.
Los pipelines batch aprovechan las capacidades de auto-scaling de Databricks para optimizar costes, escalando recursos únicamente durante la ejecución y liberándolos al completarse. Esta característica resulta especialmente valiosa para organizaciones con patrones de carga predecibles que buscan optimizar sus inversiones en infraestructura.
Ingestión en tiempo real (Streaming)
El streaming en Databricks permite procesar datos de forma continua conforme van llegando a la plataforma. Esta capacidad resulta fundamental para casos de uso que requieren análisis en tiempo real, como detección de fraudes, monitoreo de sistemas, personalización de experiencias o análisis de comportamiento de usuarios.
La implementación de streaming utiliza Structured Streaming, que proporciona exactamente las mismas semánticas que el procesamiento batch pero con latencias de milisegundos. Esta unificación permite que los equipos de desarrollo reutilicen código entre ambos modelos, reduciendo la complejidad operativa.
Change Data Capture (CDC)
El CDC en Databricks facilita la captura de cambios incrementales desde sistemas transaccionales, permitiendo mantener sincronizados los datos analíticos con las fuentes operacionales. Esta capacidad resulta crucial para mantener la consistencia entre sistemas sin impactar el rendimiento de las aplicaciones productivas.
Delta Lake, el formato de almacenamiento nativo de Databricks, proporciona capacidades avanzadas de versionado y time travel que facilitan la implementación de patrones CDC complejos, incluyendo el manejo de eliminaciones, actualizaciones y resolución de conflictos.

Arquitectura de ingestion en Azure Databricks: del source al Lakehouse
La arquitectura de ingesta en Azure Databricks implementa un enfoque multi-capa que separa las responsabilidades de captura, transformación y consumo de datos. Esta separación permite optimizar cada etapa independientemente y facilita el mantenimiento a largo plazo.
Capa de ingesta
La primera capa se enfoca en la captura eficiente de datos desde múltiples fuentes. Azure Databricks integra nativamente con servicios como Azure Data Factory, Event Hubs, IoT Hub y múltiples conectores para bases de datos relacionales y NoSQL. Esta integración permite estructurar pipelines complejos que combinan fuentes heterogéneas con transformaciones mínimas.
Capa de procesamiento
La capa intermedia implementa las transformaciones empresariales utilizando Apache Spark. Aquí se aplican reglas de calidad de datos, normalizaciones, enriquecimientos y agregaciones necesarias para preparar la información para el consumo analítico. La paralelización automática de Spark garantiza que estas transformaciones escalen según el volumen de datos procesados.
Capa de almacenamiento
Delta Lake actúa como la capa de almacenamiento unificada, proporcionando capacidades transaccionales sobre formatos de archivo estándar. Esta arquitectura permite que múltiples herramientas analíticas accedan a los mismos datos sin duplicación, reduciendo costes y eliminando inconsistencias.
Herramientas y conectores soportados para «databricks ingest»
Databricks ofrece un ecosistema extenso de conectores que facilita la integración con prácticamente cualquier fuente de datos empresarial. Los conectores nativos incluyen bases de datos relacionales (PostgreSQL, MySQL, SQL Server), sistemas NoSQL (MongoDB, Cassandra), plataformas de streaming (Kafka, Kinesis) y servicios en la nube (S3, Azure Blob Storage, Google Cloud Storage).
Integraciones empresariales
Para entornos empresariales, Databricks proporciona conectores especializados para sistemas ERP como SAP, Salesforce, Oracle y Microsoft Dynamics. Estos conectores implementan optimizaciones específicas para manejar las particularidades de cada sistema, como particionado inteligente y procesamiento incremental.
Herramientas de orquestación
La plataforma se integra de forma nativa con herramientas como Apache Airflow, Azure Data Factory y AWS Step Functions. Esta integración permite implementar flujos de trabajo complejos que combinan ingesta, transformación y análisis en pipelines automatizados y monitoreados.
Conectores para análisis
Databricks facilita la conexión directa con herramientas de visualización como Tableau, permitiendo que los usuarios finales accedan a datos actualizados sin necesidad de procesos intermedios de exportación. Esta integración acelera significativamente el ciclo de análisis y mejora la experiencia del usuario final.
Ingestión en Databricks vs Snowflake
Aunque tanto Databricks como Snowflake ofrecen capacidades robustas de ingesta, existen diferencias fundamentales en sus enfoques arquitectónicos que impactan las decisiones de implementación.
Arquitectura de procesamiento
Databricks se fundamenta en Apache Spark para el procesamiento distribuido, proporcionando flexibilidad para manejar cargas de trabajo tanto analíticas como de machine learning. Su arquitectura multi-lenguaje permite que los equipos utilicen Python, R, Scala y SQL según sus necesidades específicas.
Snowflake implementa un enfoque más centrado en SQL con optimizaciones específicas para cargas de trabajo analíticas. Su arquitectura de almacenamiento separado del cómputo ofrece ventajas en términos de escalabilidad y gestión de costes para ciertos patrones de uso.
Modelo de costes
La estructura de costes difiere significativamente entre ambas plataformas. Databricks factura por unidades de procesamiento (DBUs) que incluyen tanto cómputo como almacenamiento, mientras que Snowflake separa estos componentes permitiendo optimizaciones independientes.
Capacidades de machine learning
Databricks integra nativamente capacidades de MLOps y machine learning distribuido, facilitando la implementación de casos de uso avanzados de inteligencia artificial. Snowflake, aunque ofrece algunas capacidades de ML, se enfoca principalmente en análisis SQL tradicional.

Buenas prácticas de ingestión: rendimiento, seguridad y monitoreo
Optimización del rendimiento
Para maximizar el rendimiento de ingesta, es fundamental implementar estrategias de particionado inteligente que distribuyan uniformemente los datos entre los nodos del clúster. La configuración adecuada del tamaño de partición puede mejorar significativamente los tiempos de procesamiento, especialmente para cargas de trabajo masivas.
La compresión de datos y la selección del formato de archivo apropiado (Parquet, Delta) impactan directamente en el rendimiento de lectura y escritura. Delta Lake proporciona optimizaciones automáticas como Z-ordering y compactación que mejoran continuamente el rendimiento sin intervención manual.
Seguridad e integridad
La implementación de controles de acceso granulares resulta crucial para mantener la seguridad de los datos durante el proceso de ingesta. Databricks proporciona integración con Azure Active Directory y AWS IAM para implementar políticas de seguridad consistentes across toda la plataforma.
El cifrado end-to-end debe implementarse tanto en tránsito como en reposo. La plataforma soporta múltiples esquemas de cifrado y gestión de claves, permitiendo que las organizaciones mantengan control total sobre sus datos sensibles.
Monitoreo y observabilidad
La implementación de métricas de monitoreo proactivo permite detectar problemas de rendimiento antes de que impacten a los usuarios finales. Databricks proporciona integración con herramientas como Azure Monitor y AWS CloudWatch para implementar alertas automáticas.
El logging detallado de los procesos de ingesta facilita el troubleshooting y la optimización continua. Es recomendable implementar dashboards que visualicen métricas clave como latencia, throughput y tasas de error.
El databricks ingest representa una capacidad fundamental para organizaciones que buscan implementar estrategias de datos modernas y escalables. Su arquitectura unificada, capacidades de procesamiento distribuido y integración nativa con herramientas analíticas lo posicionan como una solución integral para los desafíos de ingesta contemporáneos.
La flexibilidad arquitectónica de Databricks permite adaptarse a múltiples casos de uso, desde procesamiento batch tradicional hasta análisis en tiempo real y machine learning avanzado. Esta versatilidad reduce la complejidad operativa y acelera el time-to-value para las iniciativas analíticas.
La implementación exitosa requiere una planificación cuidadosa que considere aspectos de rendimiento, seguridad y monitoreo desde las etapas iniciales del proyecto. Las organizaciones que invierten en diseñar arquitecturas de ingesta robustas establecen las bases para convertirse en empresas verdaderamente data-driven.
¿Estás listo para transformar tu estrategia de datos con Databricks? En The Information Lab Spain somos expertos en implementar soluciones de análisis de datos que impulsan el crecimiento empresarial. Nuestro equipo certificado te acompañará en todo el proceso, desde la arquitectura inicial hasta la adopción completa de herramientas analíticas avanzadas. Contáctanos hoy mismo para descubrir cómo podemos ayudarte a convertir tu organización en una empresa verdaderamente data-driven.