

El RMS Titanic fue un enorme barco británico que, lamentablemente, se hundió en 1912 tras colisionar con un iceberg. En el desastre, alrededor de 1500 personas perdieron la vida, dando lugar a una catástrofe marítima y al nacimiento de un icono usado en incontables ocasiones: en el cine, en la literatura, en los videojuegos y en un sinfín de productos más. En la era del machine learning, también ha dado un valioso recurso para testear algoritmos, productos y soluciones de aprendizaje automático. Y es de eso de lo que vamos a hablar hoy, de los usos de los datos del Titanic dataset, y cómo estas mismas técnicas pueden impulsar el uso de los datos en el sector empresarial para crear significativas métricas de negocio.
¿Qué contiene el Titanic dataset?
En el dataset de Titanic se incluyen los datos de los pasajeros que embarcaron en la nave, con datos descriptivos —nombre, sexo, edad, clase del billete, etc.— y si sobrevivieron o fallecieron en el naufragio.
La lista completa es:
- PassengerId: identificador único del pasajero/a.
- Ticket: identificador del billete.
- Name: nombre del pasajero/a.
- Sex: sexo del pasajero/a.
- Age: edad del pasajero/a.
- Survived: si el pasajero/a sobrevivió al naufragio, codificada como 0=no y 1=sí
- Class: clase a la que pertenecía el pasajero/a: 1, 2 o 3.
- SiblingsNumber: número de hermanos/as, hermanastros/as en el barco.
- Parch: número de padres/madres e hijos/as en el barco.
- Fare: precio pagado por el billete.
- Cabin: identificador del camarote asignado.
- Embarked: puerto en el que el pasajero/a embarcó en el Titanic.
Con el Titanic dataset se busca predecir (entre otros ejercicios) la tasa de supervivencia con base en los datos sociales de las y los pasajeros, un valioso experimento con infinidad de usos en el mundo real: predicción del precio adecuado de un producto basándose en datos demográficos, predicción de riesgos, etc.

Análisis de datos
Este es el primer paso para resolver cualquier problema de machine learning es el análisis exploratorio de datos o EDA (Exploratory Data Analysis, por sus siglas en inglés).
Los datos en crudo del dataset deben ser preprocesados y limpiados para crear variables de calidad para nuestro algoritmo de aprendizaje automático, ya que pueden existir datos faltantes en el dataset (no todos los pasajeros tienen todos los campos rellenados) o algunas variables pueden no ser relevantes para todos los casos prácticos que se desean explorar.
En este paso se analizan varios aspectos de cada una de las variables del dataset, como:
- Calidad del dato: cantidad de valores nulos, datos duplicados, datos irrelevantes (como los identificadores únicos), etc.
- Tipo del dato: si es numérico, un enumerado finito (como las clases) o alfanumérico.
- Relaciones entre los datos: detectar relaciones de calidad entre datos (hijos, padres, nacionalidad, sexo…) son la verdadera piedra angular en este tipo de algoritmos.
Una vez limpiados, preprocesados y reducidos los datos de entrada del dataset, se pueden usar diferentes algoritmos de aprendizaje automático para extraer conclusiones, como:
- ¿En qué rango de edad hubo más fallecidos?
- ¿Cuál era la posibilidad de fallecer para cada una de las clases (1ª, 2ª o 3ª)?
- ¿Influía el puerto de origen en la tasa de supervivencia?
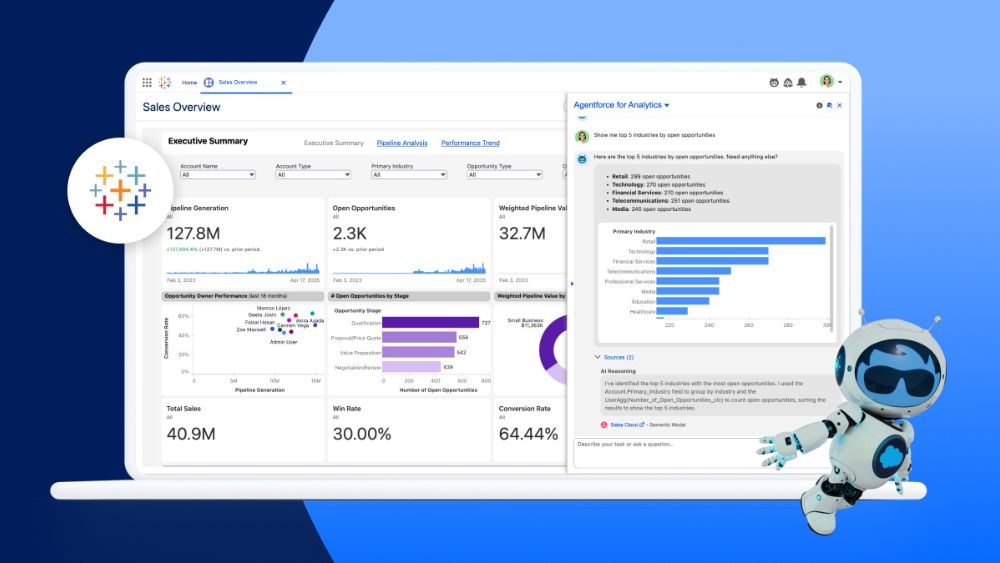
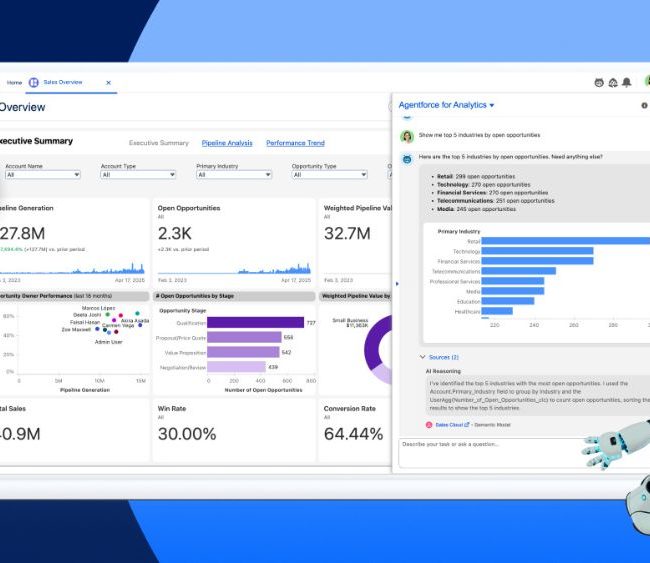
En el mundo empresarial, herramientas como las de Alteryx facilitan este preanálisis de los datos (y muchos de los procesos posteriores) necesario para desarrollar algoritmos predictivos aplicables a la toma de decisiones empresariales.
Aplicaciones del dataset del Titanic en machine learning
Es sencillo ver la correlación entre las preguntas que nos hemos realizado al analizar los datos del Titanic dataset y las necesidades de cualquier empresa.
Por ejemplo: “¿en qué rango de edad hubo más fallecidos?” es fácilmente aplicable a la pregunta “¿en qué rango de edad mi producto puede tener más éxito?” teniendo métricas de consumo segmentadas por sexo y edad.
Otro ejemplo: “¿influía el puerto de origen en la tasa de supervivencia?” es análoga a la pregunta “¿qué productos tienen más éxito para los potenciales clientes de cada región?” teniendo un dataset de productos adquiridos segmentados por nacionalidad y región de los compradores.
El análisis de los datos dentro de la empresa se ha convertido en un pilar fundamental que ayuda a la toma de decisiones y a comprender lo que funciona y lo que no gracias al análisis de enormes volúmenes de datos obtenidos del funcionamiento diario y de los datos de consumo.
Con algoritmos de machine learning cada vez más potentes, llevar los ejercicios propuestos por el Titanic dataset a los datos de nuestra empresa puede marcar la diferencia entre decisiones empresariales infundadas a la toma de decisiones basada en métricas reales y en correlaciones de datos que, sin el aprendizaje automático, serían imposibles de obtener.

La era de los datos
Para obtener métricas y KPI de calidad es necesario disponer de herramientas que sean capaces de ingerir, gestionar, preprocesar y segmentar estos enormes datasets, siempre en constante crecimiento. El uso de soluciones empresariales de análisis de datos como Snowflake, Tableau o Alteryx pueden marcar la diferencia para aprovechar de forma eficiente los datos generados por nuestra empresa.
Cada día hay más data-driven companies —empresas que usan IA y Big Data como piedra angular para la toma de decisiones—, y cada día hay más y mejores medios y productos para emprender este camino si aún no se ha iniciado.
Si estás buscando un socio tecnológico que te ayude a convertir tu empresa en una data-driven, The Information Lab es tu mejor opción. Nuestro objetivo es acompañarte en la implantación y desarrollo de una infraestructura de consumo y consulta de datos sólida que te permita dar sentido a tus datos y obtener métricas relevantes que te ayuden a consolidar las estrategias de tu empresa.
Contacta con nosotros para iniciar tu viaje y hacer que tu empresa entre también en la era de los datos.